
Episode 2
Baseline (ACT)
BeamSearch (OSA)
Search lets an embodied policy look ahead before committing to an action. We study this idea in PushT by augmenting a pretrained Action Chunk Transformer with Beam Search over perturbed action chunks.
Candidate futures are evaluated in cloned simulator states and scored with coverage-based reward. This turns single-pass ACT inference into receding-horizon action selection while keeping the learned policy as the proposal mechanism.
We also introduce One Step Ahead, a lightweight gate that first simulates the nominal policy chunk and invokes full search only when the predicted coverage change suggests that additional computation is necessary.
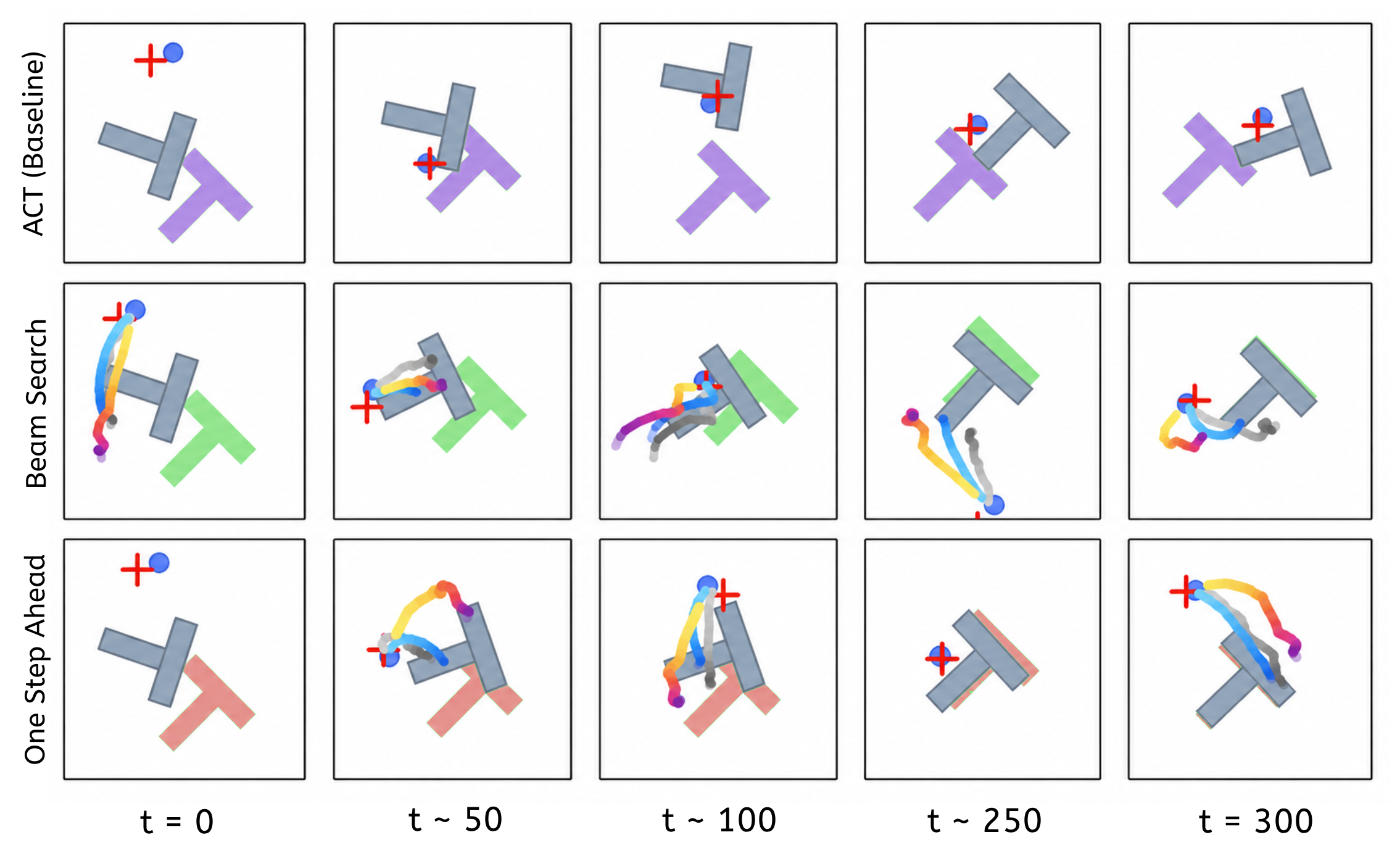
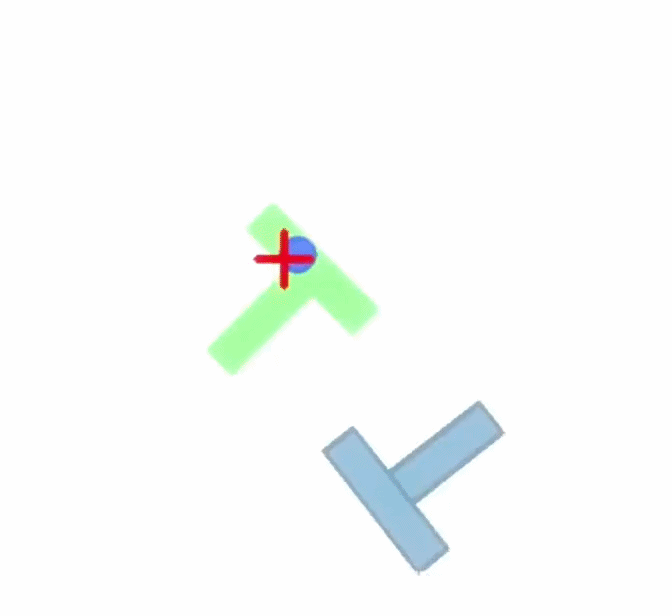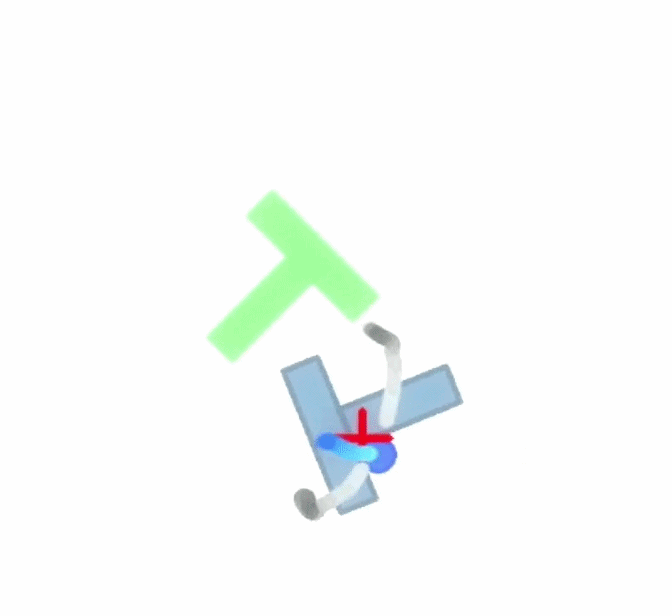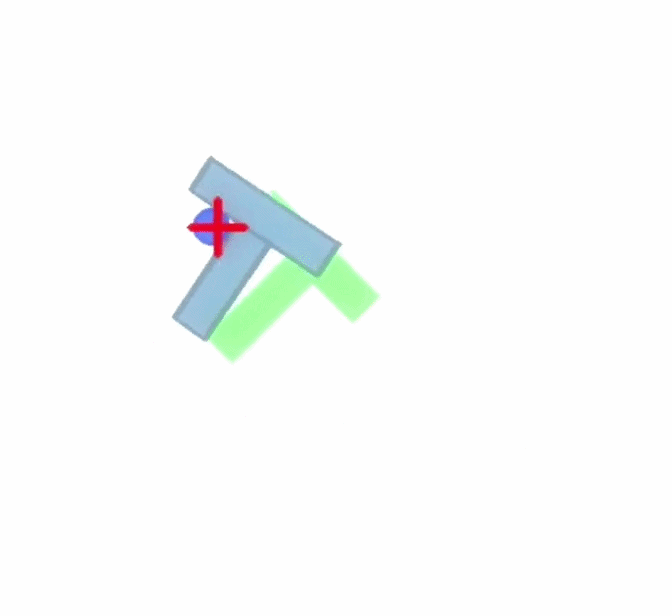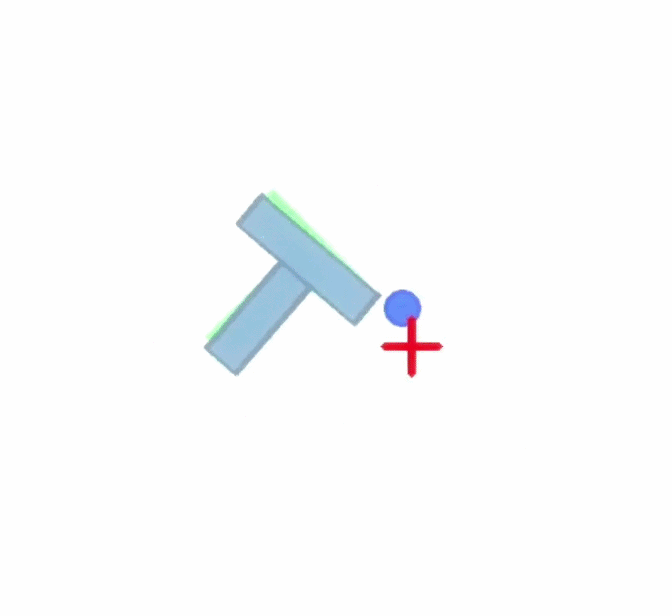
Paired PushT rollouts comparing Baseline (ACT) with BeamSearch (OSA).
Baseline (ACT)
BeamSearch (OSA)
Baseline (ACT)
BeamSearch (OSA)
Baseline (ACT)
BeamSearch (OSA)
Baseline (ACT)
BeamSearch (OSA)
Baseline (ACT)
BeamSearch (OSA)
Baseline (ACT)
BeamSearch (OSA)
Baseline (ACT)
BeamSearch (OSA)
Baseline (ACT)
BeamSearch (OSA)
Baseline (ACT)
BeamSearch (OSA)
Baseline (ACT)
BeamSearch (OSA)
At each planning point, ACT proposes a nominal chunk of 2D target actions. Beam Search constructs nearby candidate chunks, rolls them forward in the PushT simulator, and keeps the branches with the strongest coverage reward.
Full search is useful but expensive. One Step Ahead first tests the nominal ACT chunk. If that one-step simulation does not predict a harmful coverage drop, the policy action is used directly; otherwise Beam Search is triggered.
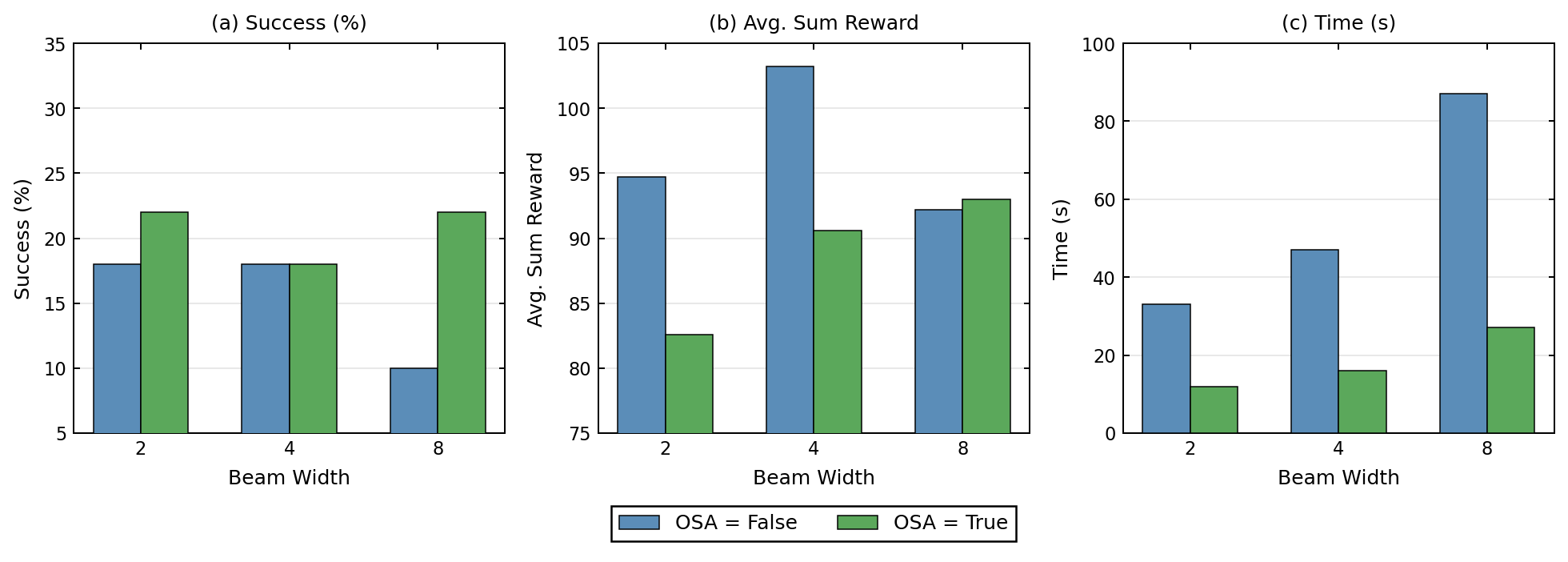
This preserves the embodied success rate in the evaluated settings while reducing runtime by roughly 2.5x to 4x.
Across 50 PushT episodes, Beam Search improves the ACT baseline from 0% to 18% goal success. Average cumulative coverage reward increases from 39.4 to 90.7, showing that search makes the policy move the T object closer to the target even when binary success is not reached.
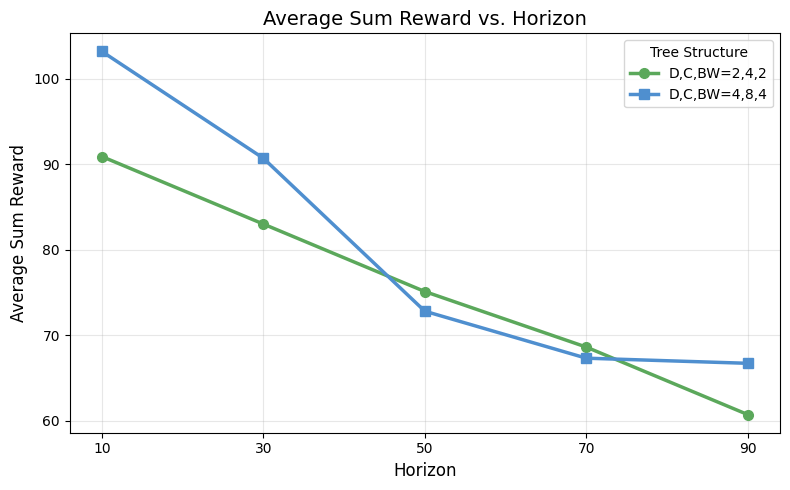
Increasing branching factor and beam width makes search more likely to select perturbed chunks over the nominal policy output. The best tested configuration achieves the highest cumulative reward, but with a large runtime cost; One Step Ahead targets this redundancy by reserving full search for states where the nominal action appears risky.
| Method | D | C | BW | Avg. Sum Reward | Avg. Max Reward | Success (%) | ASR (%) | Runtime (s) |
|---|---|---|---|---|---|---|---|---|
| Beam Search | 2 | 4 | 2 | 90.9 | 0.77 | 18 | 56.4 | 14 |
| Beam Search | 4 | 2 | 2 | 90.8 | 0.78 | 16 | 37.5 | 10 |
| Beam Search | 4 | 4 | 2 | 90.9 | 0.77 | 18 | 58.23 | 10 |
| Beam Search | 4 | 8 | 2 | 94.7 | 0.77 | 18 | 75.6 | 33 |
| Beam Search | 4 | 8 | 4 | 103.2 | 0.81 | 18 | 75 | 47 |
| Beam Search | 4 | 8 | 8 | 92.2 | 0.80 | 10 | 78.5 | 87 |
| Beam Search | 8 | 4 | 2 | 90.9 | 0.77 | 18 | 58.23 | 16 |
| ACT (Baseline) | - | - | - | 39.44 | 0.36 | 0.0 | - | 2 |
@misc{zeer2026lookahead,
title = {Look Ahead: Search-Driven Reasoning in Language and Embodied AI},
author = {Zeer, Ahmed and Shbib, Osama and Yuce, Muzaffer Kaan and Kesgin, Himmet Toprak and Amasyali, Mehmet Fatih},
year = {2026}
}